Scraping the Surface of Airtable (Part 2)
 Photo by jimmy teoh from Pexels
Photo by jimmy teoh from Pexels
Before we start, let’s appreciate the fact that the first part is 2 yrs old! Anyway, after 2 years of working on another things, I came back around to the same problem today. Still the same idea as part one, that is how can i connect multiple bases without the need of logging into airtable. This part will be built on top of the first one, or to summarize: turns out I’m on the right track and requestId doesn’t really matter too much, maybe I made mistake in copying it in the last post? Anyway in this post I will talk about several things:
- Why I choose not to use Airtable API?
- Why I decided to use native requests and didn’t use headless browser
- My current solution using only requests and regex (its not pretty but it works :))
- Where can I go from here
If you want to follow along you can find the notebook and source code on my github or you can run it on google colab. If you just want to use the package, you could install it from pip. And use the code on your own risk, as this behavior is not guaranteed to be consistent over time (I don’t know if airtable team decide to change it anytime soon). Okay, first let’s address the elephant in the room.
Why Not Airtable API
2 years ago when I was writing the first part, the API itself is still a work in progress by the airtable team, so basically I have no choice but to scrap my data. But today, after airtable has official API support, why do I decide not to use the API anyway? I have three main reasons:
- The API is rate limited to 5 requests per second as of today, and my current base has already multiple services hitting the API. So as to minimize the risk of hitting the rate limit and incur the 30 seconds penalty, I decided to not use the official API.
- I want to create the solution that could work just by using the table shared link. so that the accessible scope can be limited to only access certain part of the base (not the whole bases itself),
- And lastly, it seems fun doing this kind of thing sometimes :)
So, because of those three reasons I decided to create the solution which could work by only using the shared view link. But for any other purposes I really recommend using their official API, as it’s the way it’s intended to be :D.
Why not Headless Browser
Using headless browser I could simply head over to the link, and click on the “Download CSV” button and be done with it. And to be honest it seems to be a better option, but I want the solution to be as “light” as possible, and headless browser is not the smallest program out there. Thus I decided to work by onnly using the minimal amount of python packages. In this case, the solution practically only need beautifulsoup4 to works.
Current Solution
If you want to try this out without creating a new base, you could use my experimentation base to follow along.
Create a Custom View and Create a Secret Link
I’m still using the same method as the first part, and the first thing i need to do is create the secret shared view link. To do so, just head over the table of interest, in this case we will use the Stories table, and All stories view. Then click on the Share view button and copy the generated grid view link. Oh, don’t forget to keep the Allow viewers to copy data out of this view activated.
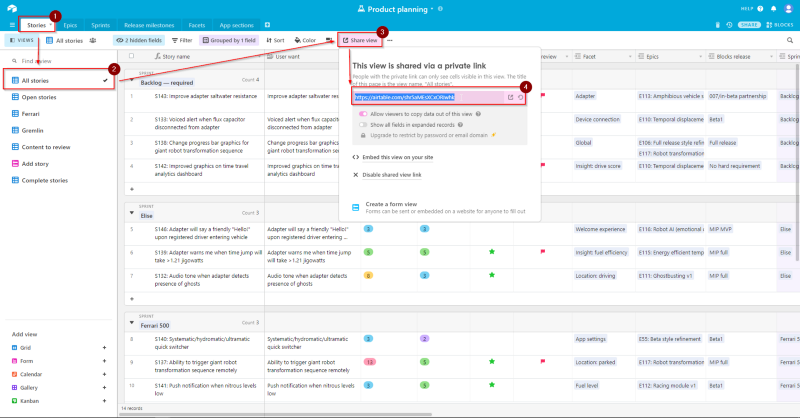
For the rest of this article we’ll use the shared view link generated from that base: https://airtable.com/shr5aMEsXCxORIwhk
Get the necessary Information From the Response
What Necessary Info??
I’ll explain a bit how I decided what is necessary information here. The first thing I did was to fire up the devtools and look at network tab, then click that “Download CSV” button. I found this to be the request fired by my browser to download the CSV.
https://airtable.com/v0.3/view/viwJuiikzJnQ0cyqj/downloadCsv?x-time-zone=Asia%2FJakarta&x-user-locale=en&x-airtable-application-id=app7CUJtL7vQWbiDA&stringifiedObjectParams=%7B%22origin%22%3A%22viewMenuPopover%22%7D&requestId=req18VeOicyq8MN7f&accessPolicy=%7B%22allowedActions%22%3A%5B%7B%22modelClassName%22%3A%22view%22%2C....
What does that even means? To find out, I head over to Postman and let it parse the parameter for me. The result, the request hits the endpoint of https://airtable.com/v0.3/view/{viewId}/downloadCsv?{query_params} with viewId as the id of our shared view, and the query params as shown below.
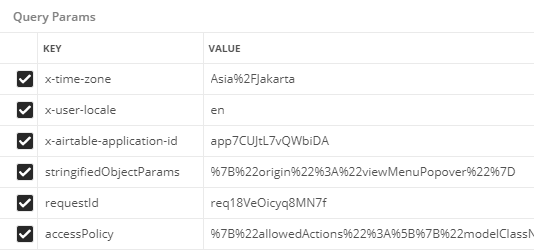
Okay, the next task that we need to do is finding out which parameter is necessary and how to generate them. I did it by eliminating one parameter at a time. After an hour of trial and error, I found out that practically no header need to be explicitly set. And for the request to succeed we need the following parameters:
- The
viewIdthat is regenerated each time I load the page AccessPolicythat indicates what we are permitted to do in the sharedAppIdI don’t know what it indicates, but when I remove this parameter, the request always failedLocalethat indicates our machine locale, I just use the default en value as I haven’t bothered to find out other permitted value for thisTimezonethat is used to convert the time column in the view, according to user timezone.
With those in mind let’s move on to retrieve those data from the shared view page.
Retrieve those information
After trying another GET requests to the shared view url, and search for the parameters name, I found that the script tag right after the title tag contains all the necessary information that’s needed.
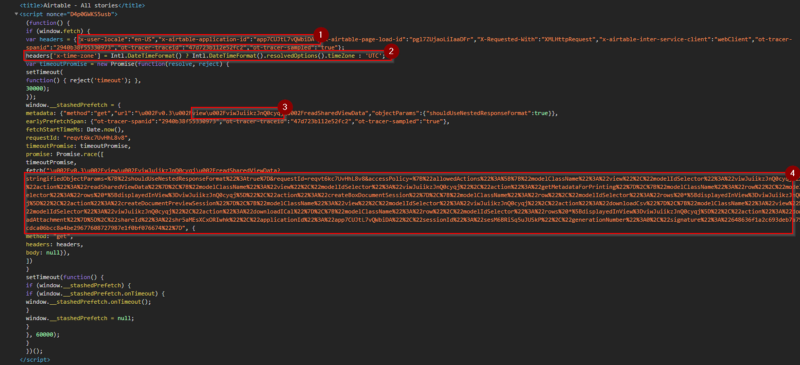
After finding out where the wanted information are, we could Use some regex magic to extract those information (if you want to know how the regex works try regexr.com will help a lot in understanding what the patterns do).
view_id = re.search(r"(viw[a-zA-Z0-9]+)",str(script)).group(1)
access_policy = re.search(r"accessPolicy=([a-zA-Z0-9%*]+)",str(script)).group(1)
app_id = re.search(r"\"x-airtable-application-id\":\"(app[a-zA-Z0-9]+)",str(script)).group(1)
Build URL to Download CSV and Fire!
With those parameters the last step is building the URL needed to download the CSV, and use it to send the GET requests.
self.csv_url = f"https://airtable.com/v0.3/view/{self.view_id}/downloadCsv?"
for (k,v) in self.params.items():
self.csv_url += k+"="+v+"&"
self.csv_url = self.csv_url[:-1]
r = requests.get(self.csv_url)
r.encoding = "utf-8"
r.text
It will return the CSV data that we want as a string. You could save it into file, or use StingIO to feed it into pandas, and so many more. By the way, I think airtable use UTF-8 to encode the CSV data, so make sure to change the response encoding after receiving the requests.
Finished Script
Again, if you just want the finished product, You can clone the finished package from my github repository, or install it using pip and use it as a CLI.
# install the package
pip install airscraper
# pull data and put it into csv
airscraper {url}
Where to go from Here?
Well, there are several things that we can expand upon this idea
- Create google function to serve as endpoint to backup airtable view
- Use it as part of ETL pipeline (like airflow, singer, etc.)
- Deploy a cron job calling this script to backup the data into your server
For the next part I think I’ll go over how to use this as part of ETL pipeline in Google Cloud Platform using Functions and BigQuery, but seeing it took two whole years for me to continue the first one let’s see how long it’ll take me for the next part :) For now, thanks for reading and if you’re interested in further discussion, feel free to hit me up in the comment or on my twitter @BanditelolRP